
In the world of data engineering, the ability to efficiently manage workflows, especially when dealing with large datasets, is critical. Serverless tasks in Snowflake have emerged as a highly effective solution, allowing data teams to scale and execute tasks without the overhead of managing resources directly. If you’re aiming to optimise runtime and enhance concurrency, Snowflake’s serverless tasks could be exactly what you need.
What Are Snowflake Serverless Tasks?
Snowflake serverless tasks offer an on-demand compute solution designed to automate scheduled or event-driven tasks without requiring a dedicated virtual warehouse. This feature allows you to schedule SQL-based tasks or combine multiple tasks into workflows with highly variable demands, all while avoiding the need to manually configure and allocate compute resources.
Key Benefits of Snowflake Serverless Tasks
- Automatic Scaling
Serverless tasks automatically scale to handle workload demands, providing more resources for complex tasks or larger data volumes without manual intervention. This dynamic scaling makes it ideal for workflows that experience irregular spikes in demand. - Optimised for Concurrency
Traditional task management often struggles with high concurrency requirements, but Snowflake serverless tasks are designed to handle concurrent executions seamlessly. For instance, configuring tasks to run up to 100 instances in parallel allows for efficient processing of large datasets, dramatically reducing total runtime. - Reduced Management Overhead
Unlike traditional compute setups where resource management and scaling require close monitoring, serverless tasks eliminate the need for such maintenance. This frees up your team to focus on high-value analytics tasks rather than infrastructure management. - Cost Efficiency
With serverless tasks, you only pay for the compute time consumed by the tasks. This is especially beneficial for workloads with fluctuating demands, as you avoid the cost of idle resources, paying only for what you actually use.
Serverless Tasks in Action: A Real-World Example
To highlight the efficiency of Snowflake serverless tasks, we tested their performance by ingesting 200 tables from an Azure Data Lake into Snowflake using the Dynamics 365 Connector. Each table held around 140,000 rows, stored as 100MB CSV files. Our goal was to compare the performance and cost of serverless tasks against a dedicated virtual warehouse for this high-concurrency workload.
Initial Results with a Dedicated Virtual Warehouse
Using a dedicated XS virtual warehouse, we configured the process to handle 30 tables concurrently. This setup avoided any queuing or blocking, resulting in a stable runtime.
When we attempted to increase the concurrency to 50 tables in the dedicated XS warehouse, however, severe queuing and blocking occurred. This queuing caused the overall process to take four times longer compared to the 30-table setup. To avoid this limitation, we would need to upgrade the virtual warehouse to a larger size, which also increases costs.
Improved Results with Serverless Tasks
To overcome the limitations observed with the dedicated warehouse, we configured the process to use Snowflake’s serverless tasks. With serverless tasks configured to an XS initial size, we were able to process 100 tables concurrently without experiencing any queuing. This setup allowed us to maximise concurrency, as serverless tasks automatically scaled up to meet demand and then scaled down after the task finished.
Test Results
- Test 3.2 (Serverless Tasks) Processed 100 tables concurrently
- Test 3.3 (Dedicated XS Virtual Warehouse) Processed 30 tables concurrently
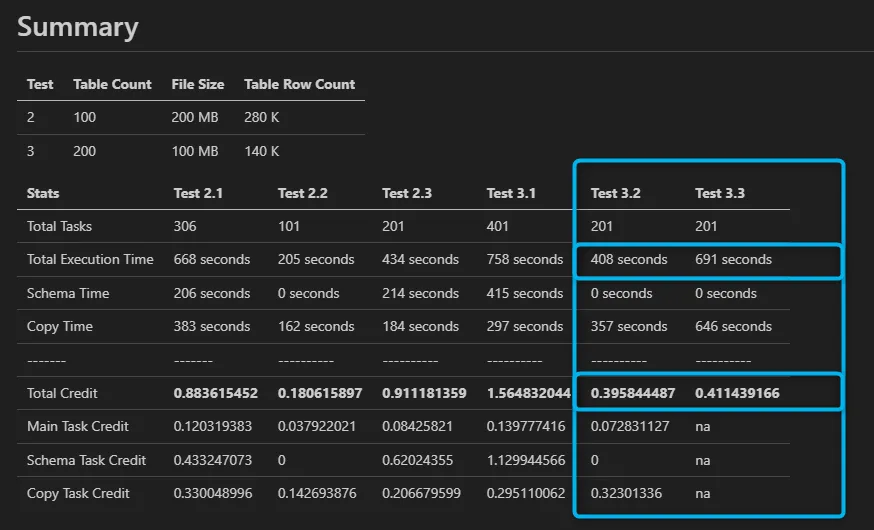
Key Findings
The serverless task configuration proved to be 41% faster and 3.8% cheaper compared to using the dedicated XS virtual warehouse. Serverless tasks not only improved performance by significantly reducing runtime, but they also offered cost savings by adjusting compute resources dynamically based on demand. This experiment clearly demonstrates the value of Snowflake’s serverless tasks in handling high-concurrency workloads with better speed and lower costs.
Getting Started with Snowflake Serverless Tasks
Setting up Snowflake serverless tasks is straightforward:
- Define Your Task
Use Snowflake’s SQL-based task creation to define the process you want to automate. Define the schedule or event that will trigger the task, such as data arrival in a specific table. Instead of the traditional parameter WAREHOUSE, use task parameters SERVERLESS_TASK_MIN_STATEMENT_SIZE, SERVERLESS_TASK_MAX_STATEMENT_SIZE and/or USER_TASK_MANAGED_INITIAL_WAREHOUSE_SIZE to define compute sizing for serverless tasks. - Optimise for Parallel Execution
Where applicable, break down larger workflows into discrete tasks that can run in parallel. Snowflake serverless tasks support this approach, so take advantage of the flexibility to run concurrent processes. - Monitor and Adjust as Needed
Although serverless tasks minimise the need for manual intervention, it’s helpful to monitor performance metrics. Snowflake’s tools offer insights into task runtimes, concurrency, and usage patterns, allowing you to fine-tune configurations for even better efficiency.
See more details from Snowflake’s documentation.
Tips for Leveraging Snowflake Serverless Tasks
- Use Event-Based Triggers: For event-driven tasks, set up triggers to initiate tasks based on specific data stream. This way, you ensure that your processes begin as soon as the data is available, minimising delays.
- Partition Data for Efficient Processing: Where possible, partition data in a way that allows independent chunks to be processed concurrently. Serverless tasks handle parallelism well, so make the most of this feature.
Conclusion: Elevating Your Data Pipeline with Snowflake Serverless Tasks
Snowflake serverless tasks provide an efficient way to streamline workflows, reduce runtime, and support high concurrency. By minimising management overhead and scaling dynamically, serverless tasks free data teams to focus on delivering valuable insights. Whether you’re running daily ETL jobs or processing extensive datasets on demand, Snowflake serverless tasks can help you scale effectively and cost-efficiently.
As data demands grow, embracing serverless architectures like Snowflake’s can be a transformative step towards a more agile and responsive data platform.
Special Thanks
A special thanks to Regan Murphy from Snowflake for your insights on the Serverless Tasks, which have helped us unlock new levels of efficiency and performance in our workflows. Regan’s insights have been instrumental in demonstrating the value of serverless compute and guiding us towards a more scalable data architecture.